Conteúdos sobre cloud computing, data centers, infraestrutura, automação e alta performance para profissionais e empresas que buscam tecnologia de ponta
DataOps é uma metodologia automatizada e orientada a processos, usada por equipes analíticas e de dados, para melhorar a qualidade e reduzir o tempo de ciclo da análise de dados.
Ele funciona por meio da combinação dos conceitos do DevOps, do Ágil, além do controle de Processos Estatísticos que traz boas práticas capazes de eliminar as complicações e as barreiras existentes entre as operações analíticas e as áreas de desenvolvimento.
Funcionamento na prática O DataOps interliga de modo perfeito, todas as equipes englobadas no ciclo de dados, com o intuito de usá-los e explorá-los favoravelmente às empresas, com agilidade e em níveis de governança adequados. Voltada à colaboração entre desenvolvedores, analistas de infraestrutura, equipes de apoio e especialistas em dados, ele reúne a ciência de dados e a engenharia de dados com o conceito DevOps. O seu objetivo é fazer o desenvolvimento dos projetos de dados com qualidade ímpar, para que dessa forma, os insights analíticos mais valiosos sejam entregues em tempo reduzido.
O DataOps se encaixa melhor aonde? Para aplicar o DataOps, é interessante contar com o apoio de profissionais com conhecimento em data science e engenharia de software. Com o apoio dessas equipes a performance é otimizada significativamente. O conceito é palpável para qualquer tipo de trabalho que faz o uso de dados e se encaixa perfeitamente na arquitetura de microsserviços.
Como implementar o sistema na minha empresa?
Alinhe a sua equipe de TI
Primeiro, para poder implementar o DataOps no seu empreendimento, é importante alinhar a sua equipe de TI, pois a ferramenta busca a integração profissionais e das áreas.
Realize teste dos fluxos de dados Segundo, a fase de testagem dos fluxos de dados. É interessante promover testes autônomos a fim de assegurar o controle do modo de como os seus dados são coletados, processados e avaliados.
Use em diversos ambientes de trabalho Por ultimo, a implementação do DataOps deve envolver toda a empresa, colocando as ideias em práticas da ferramenta em outros ambientes, como: em computadores extras, ambientes virtuais e em containers.
Os maiores benefícios do DataOps
O sistema avalia o seu processo As práticas baseadas em DataOps, é capaz de otimizar todos os processos envolvendo os dados, dessa forma, o DataOps garante a melhor entrega possível dos dados, e de quebra, ainda traz análises de seus processos.
Aprimora a colaboração Você consegue ter vários profissionais de áreas diferentes operando de modo simultâneo em fases diferentes do seu projeto. E toda essa troca é proporcionada pelo DataOps, o mesmo pode ser feito em qualquer etapa com seus próprios clientes.
Reduz as taxas de erros Com o DataOps, a quantidade de falhas e erros diminui, isso ocorre porque o sistema de gerenciamento é muito mais automatizado, com versionamento e governança de tudo que tange aos dados.
Diminui o período do ciclo de mudança O DataOps acelera significativamente o tempo do ciclo de mudança, por conta dos constantes testes que avaliam e monitoram de modo muito mais eficiente e veloz. Na era digital, a excelência dos dados é indispensável para te manter competitivo e eficiente, por isso é sempre importante poder implementar as melhores inovações.
A tecnologia RAID (Redundant Array Of Independent Disks) está se popularizando no setor empresarial, oferecendo soluções de armazenamento de dados e assegurando que o acesso às informações necessárias aconteça de forma eficiente e em tempo hábil. Podemos definir como uma tecnologia utilizada para fazer o gerenciamento de drives de forma independente. O objetivo é proporcionar o aumento no desempenho das máquinas e também garantir maior segurança de dados.
O que é a tecnologia RAID?
O termo Redundant Array of Independent Disks significa Matriz Redundante de Discos Independentes. Ou seja, que os vários HDDs ou SSDs presentes em uma máquina se combinam e formam uma unidade lógica. Dessa forma, os dados que são armazenados em um drive se tornam disponíveis nos demais.
Essa tecnologia é útil para as empresas porque em caso de falha em um determinado drive, os dados importantes continuarão disponíveis por meio dos demais.
Pelo fato do formato ter se popularizado bastante, novos tipos foram surgindo para atender a objetivos distintos. Mas não existe uma escolha correta, as opções precisam ser analisadas cuidadosamente de acordo com a ocasião, visto que cada contexto pede um tipo diferente de RAID.
RAID 0 (zero)
Usa tecnologia de striping, fracionamento dos dados, esse modelo de raid não gera redundância dos dados. Uma vez que partes os dados são gravados em dois ou mais discos ao mesmo tempo, a velocidade de transmissão é multiplicada pela quantidade de discos disponíveis. Visando uma maior performance de transmissão dados esse tipo de raid não oferece proteção contra falhas.
RAID 1 ou espelhamento
O RAID 1 funciona com base no espelhamento de um drive em outro. Dessa forma, é feita uma espécie de cópia mútua entre os HDDs ou SSDs envolvidos no processo. A segurança dos dados é o primeiro aspecto que deve ser considerado a respeito desse modelo.
RAID 2
O RAID 2 não é um modelo muito difundido atualmente. O motivo para isso está ligado ao fato que os HDDs atuais saem de fábricas com mecanismos bastante similares às
suas principais funcionalidades e, portanto, já têm a capacidade de prevenir determinadas situações com um mecanismo de detecção de falhas do tipo ECC (Error Correcting Code).
RAID 3
O RAID 3 é uma tecnologia que funciona com base nas divisões de drives da matriz. Entretanto, um deles é a exceção e se torna responsável por realizar o armazenamento de dados com base na paridade. A recuperação é feita usando os códigos de correção de erros combinados com os dados distribuídos nos outros HDs (trabalhando como Raid 0 ). Suas principais vantagens são transferência de grandes volumes de dados e também a confiabilidade no que se refere à segurança.
RAID 4
O RAID 4 se assemelha bastante ao RAID 3. Mas, o seu diferencial está na possibilidade de reconstruir dados por meio de um mecanismo de paridade. Quando se fala a respeito de arquivos maiores, ele é o mais indicado para garantir a integridade das informações.
RAID 5 e RAID 6
Raid 5 é uma evoluções das versões 2, 3 e 4 . Onde a paridade no sistema utiliza o espaço equivalente o disco inteiro, o RAID 5 a paridade é armazenada de forma alternada em todos os discos. Se qualquer dos discos contidos no sistema tiver qualquer tipo de problema, o mesmo poderá ser substituído e reconstruído através do processo chamado de rebuild. Assim como no Raid 6 é similar, mas utiliza o dobro de dados de bits para paridade nele.
As similaridades do RAID 5 e do RAID 6 justificam que a sua abordagem seja feita de forma conjunta.
RAID 10
O RAID 10 possui características que se assemelham aos modelos 0 e 1. Pode ser usado com mais de 4 drives e precisa que os HDDs sempre sejam instalados em
números pares. Isso acontece visto que a metade deles será responsável pelo armazenamento enquanto a outra cuidará das cópias.
Por conta dessas características, atualmente o RAID 10 é considerado a modalidade mais segura. Oferecendo segurança aos dados, as falhas podem acontecer em mais do que dois drives ao mesmo tempo sem perda.
Como os ambientes RAID ajudam nasegurança de dados?
A tecnologia RAID é capaz de garantir a diminuição do tempo de leitura, fazendo com que a velocidade de acesso aos dados seja reduzida. Portanto, uma vez que a empresa se vê diante de algum cenário crítico, os seus registros podem ser rapidamente acessados ou, em casos mais extremos, recuperados.
Como implementar uma tecnologiaRAID?
A implementação de uma tecnologia RAID pode ser realizada de duas maneiras: por meio de hardware e de software. Portanto, tudo depende do desempenho dos servidores da empresa e da sua segurança. Dessa forma, o modo de instalação deve ser definido pelo setor de TI ou por consultorias externas.
Hardware
Para a implementação do RAID por meio de hardware será preciso instalar os componentes. Existem placas-mãe que trazem controladores onboarding para RAID.
Caso as da empresa se encaixem nessa opção, basta conectar os drives nas portas que são administradas pelo controlador RAID.
Software
A implementação de RAID por software é mais simples. Para configurar a tecnologia RAID, será necessário dois ou mais discos de mesma velocidade e tamanho, e basearessa implementação nos sistemas operacionais que disponibilizam essa funcionalidade.
Diante da pandemia, muitas empresas tiveram de aderir ao home office, e devido a isso, serviços de nuvem, em essencial o Iaas (Infraestrutura como Serviço) aumentaram muito. Isso se dá devido justamente por conta da facilidade ao acesso de dados da empresa sem a necessidade da atuação presencial, além de garantir a segurança dos dados e informações da organização. Um estudo da Gartner, líder em pesquisa do segmento de tecnologia, apresentou dados que demonstram essa expansão: no primeiro ano da pandemia, 2020, o aumento global do consumo de nuvem (IaaS) foi de 40,7%. Outro estudo, de 2020, realizado pela IBM em conjunto com a IDC (International Data Corporation), apresentou dados exclusivos sobre o consumo da nuvem no Brasil. A pesquisa levantou que, dentre as empresas entrevistadas, 59% utilizam algum tipo de nuvem. Desse montante, 33% fazem uso de nuvem pública, 31% consomem nuvem privada on– premise e 27% apostam na nuvem privada com hospedagem em provedor. Após as experiências notadas no trabalho remoto durante a pandemia ficou claro o aumento do cloud computing e que a tendência é que as empresas invistam em tecnologia cada vez mais.
O foco mudou e as expectativas do mercado agora estão voltadas para a agilidade que o digital oferece, aliada à produtividade e facilidade de adaptação e migração. Diante deste cenário de amplo crescimento, em que todos os tipos de empresas, de diversos segmentos, têm procurado investimentos em tecnologia com especial destaque para a nuvem, fica claro que esta ferramenta é uma aposta certeira. A nuvem apresenta inúmeras vantagens e, além disso, se trata de uma tendência mundial para os próximos anos, no trabalho remoto e fora dele.
Por que a nuvem cresceu tanto?
O cloud computing ganhou esse destaque durante o período de pandemia e home office exatamente por facilitar o acesso aos dados da empresa sem a necessidade da atuação presencial e por oferecer isso garantindo a segurança dos dados e informações da organização. O cloud também permite o compartilhamento de forma eficaz e ágil, resultando no aumento da produtividade dos colaboradores, o que era um receio de líderes e diretores de empresa: a queda no rendimento do trabalho e, consequentemente, perda de prazos e trabalhos com menos qualidade.
As expectativas para o pós-pandemia
O foco mudou e as expectativas do mercado agora estão voltadas para a agilidade que o digital oferece, aliada à produtividade e facilidade de adaptação e migração da computação em nuvem. Essa nova forma de atuação inclui ainda um novo meio de trabalho, o modelo híbrido, que muitas organizações estão aderindo: uma parte do trabalho é feito presencialmente e outra parte via home office.
Então vale a pena investir na nuvem?
A nuvem apresenta inúmeras vantagens e ainda se trata de uma tendência mundial para os próximos anos, no trabalho remoto e fora dele. Independente do segmento da empresa, seja ela indústria, serviços, e-commerce, gastronomia, educação, a nuvem tem poder para atender às principais demandas de tecnologia inerentes à atuação dessa ferramenta, então respondendo a pergunta: com toda certeza.
Os servidores são desenvolvidos para transmitir informações e fornecer produtos de software a outras máquinas que estiverem conectadas por meio de uma rede, garantindo eficiência e agilidade. No entanto, para aguentarem as mais pesadas cargas de trabalho elas demandam de uma memória preparada e de um disco rígido de alto desempenho. Dessa forma, uma vez que um destes elementos venha a falhar, é possível que ocorra lentidão e que diversos problemas possam aparecer. Descubra como identificar as principais causas para estas questões e resolvê-las da melhor maneira possível.
Pouca memória RAM A memória RAM pode ser considerada um item crucial. Quanto maior for esta memória disponível, mais ela consegue acessar diversos arquivos e conteúdos ao mesmo tempo, acelerando o processo e permitindo que todas as tarefas sejam executadas com rapidez. Se a memória for menor, o acesso a estes arquivos será mais restrito, e a execução de diferentes tarefas ao mesmo tempo se tornará mais lenta, tornando- se o motivo para a lentidão do servidor. A solução será a instalação de mais módulos, aumentando a memória RAM para suportar todas as demandas da máquina.
Aparecimento de Malwares Um dos principais causadores para o seu servidor estar lento é a presença dos malwares. Quando um malware se instala em seu computador, ele infecta a máquina e se espalha por vários lugares, ele passa a consumir uma grande quantidade de memória do seu aparelho, causando o desempenho extremamente lento de programas vitais, como o navegador ou o sistema operacional. O recomendado para resolver esta questão é praticar um protocolo de segurança, usando os melhores produtos de software disponíveis no mercado. A fim de evitar que os usuários carreguem arquivos infectados nestes ambientes, estes programas surgem para monitorar, configurar e realizar a manutenção.
A importância da CPU O desempenho da CPU é extremamente importante para que o servidor também funcione de maneira mais adequada, sua alta utilização, com um aumento repentino e excessivo, pode ser um problema a ser considerado.
Uma CPU que está enfrentando problemas pode deixar o banco de dados mais lento, acarretando outras questões que se alastram além da lentidão. É importante considerar a atualização para uma unidade de CPU de classe superior, quanto mais potente ela for, menor será a tensão quando for encarregada de vários aplicativos e solicitações. E assim será melhor a sua performance, garantindo agilidade e menos lentidão.
Dificuldades com o processador Às vezes, o processador pode ser inadequado para a sua demanda e não conseguir suportá-la. Isso faz o retorno ser mais demorado e tudo ocorre com mais lentidão na sua máquina. O interessante é realizar a troca para um processador que seja considerado mais potente e que possa atender a todos estes detalhes que o seu uso necessita.
Problemas de armazenamento: SSD vs HDD A maioria dos computadores de uso doméstico conta com um HDD de 5.400 rotações por minuto. Mas esta característica afeta o retorno na recuperação de dados e se tornando uma possível razão para a lentidão nos seus servidores. A fim de solucionar a questão, é fundamental que o usuário possa compreender se o caminho não é obter um HDD de maior velocidade de rotações. Os modelos SAS de 10 mil e 15 mil RPM (rotações por minuto) podem apresentar uma resposta rápida para esta questão. Outra alternativa é fazer a troca por um Solid Static Drive (SSD), que possui um conceito diferente do Hard Disk Drive (HDD) e uma velocidade infinitamente maior.
O software utilizado Em alguns casos o problema não está especificamente na lentidão do servidor em si, mas em um software específico que pode ser ineficiente para a demanda. O servidor pode estar rodando normalmente outros programas e tendo problemas apenas com um, que é a causa para deixar tudo mais lento. Assim, é importante que você possa observar se esta aplicação em particular pode ser substituída ou se ela é realmente primordial para você, além disso faz-se necessário que a realização sempre de testes de qualidade em todas as aplicações instaladas.
A localização do servidor Digamos, por exemplo, que o seu servidor esteja nos Estados Unidos, quando o usuário clicar no site terá que esperar a informação atravessar diferentes fronteiras geográficas para chegar até a tela do aparelho, por esta razão, é importante considerar que essa linha imaginária a ser percorrida pode influenciar na lentidão Sendo assim, a melhor forma é considerar seu público-alvo e perceber se a maioria de seus visitantes residem no país, optando por um data center localizado na mesma região.
O desempenho do Data Center O Data Center é projetado para concentrar os servidores. Por isso é primordial que seu desempenho seja maximizado, garantindo que nada irá interferir na velocidade dos componentes que ali estão. Se houver diferentes ambientes que não possuem manutenção adequada ou têm sistemas de refrigeração mantidos de forma incorreta, poderá causar problemas recorrentes e lentidão. Por isso é importante que você possa testar se a infraestrutura do data center é capaz de suportar os níveis de desempenho demandados e aguentar diferentes cargas. Opte por analisar o tamanho de seus dados, o volume de uso, e observe que tipo de ambiente será necessário.
Cloud NAT é um servidor Linux ou Windows, igual o Cloud Server, porém rodando em rede privada em vez de ter IP Público exposto na internet. É considerado o ambiente mais seguro para qualquer tipo de aplicação. . Eis algumas dúvidas frequentes sobre o Cloud Nat:
O Cloud NAT tem acesso SSH ou RDP? Sim, tem acesso SSH total root para os servidores Linux e acesso RDP total Administrator para os servidores Windows. . O Cloud NAT tem SSL incluso? Sim, a partir do painel é possível configurar o SSL do seu domínio para Letsencrypt gratuito ou enviar um certificado SSL próprio.
É possível aumentar ou diminuir o plano do servidor?
Sim, você pode aumentar e diminuir o plano do seu servidor, a qualquer momento direto no painel com facilidade.
Como Funciona os backups?
No painel do servidor, você consegue criar e restaurar backups com 1 click a qualquer momento. Também é possível configurar rotinas de backup semanal gratuitamente ou contratar o serviço de backup diário.
A utilização do docker é uma das formas mais simples de você realizar o deploy de sua aplicação num servidor. Neste artigo iremos entendeComo utilizar o Docker para fazer deploy de sua aplicação, criando o seu docker file.
Sempre que há migração de aplicação entre servidores ou a criação de um novo ambiente operacional, é preciso refazer toda a configuração em uma nova máquina virtual, exigindo uma quantidade de tempo e trabalho considerável. Devido a essas situações que por repetidas vezes ocorriam, uma das tecnologias que se tornaram muito populares nos últimos anos foi a de containers. Veremos algumas vantagens de adotar essa abordagem, que a princípio parece ser mais trabalhosa, entretanto, reduz o trabalho de reimplantação a próximo de zero. Veremos como construir uma aplicação web, utilizando PHP FastCGI e Nginx, além de instalar automaticamente o composer e seus pacotes.
Todos os arquivos utilizados neste post podem ser encontrados em: https://github.com/goodeath/absamPosts/tree/master/docker-app
Docker
É importante deixar claro que a tecnologia de containers e Docker são duas coisas distintas. Os containers se tratam de um tipo de virtualização. Já o Docker é uma implementação concreta dessa tecnologia. Esta opção foi escolhida por ser bastante popular, robusta e open source. Toda vez que utilizarmos o termo Docker trataremos do software .
Docker Compose
É uma ferramenta do docker, utilizada para construir e configurar múltiplos containers Docker simultaneamente. É possível iniciar todos os seus serviços através de um arquivo de configuração (docker-compose.yml) com apenas um comando. Pode ser utilizado em todos os ambientes: produção, testes, desenvolvimento, etc.
Dockerfile
Se trata de um arquivo de configuração, assim como o docker-compose.yml, utilizado para dar instruções durante a criação dos containers. Podemos utilizá-lo para baixar arquivos, instalar pacotes, executar comandos shell, etc.
Iniciando
Devemos instalar os pacotes do Docker. Basta executar o comando:
$ apt install docker.io docker-compose -y
uma vez instalado, podemos verificar a instalação do docker executando:
$ docker -v
A saída deve ser algo como: Docker version 18.09.7, build 2d0083d. Para verificar a instalação do Docker Compose, podemos executar:
$ docker-compose -v
A saída deve ser algo como: docker-compose version 1.17.1, build unknown. Caso haja problemas com a instalação dos pacotes, visite https://docs.docker.com/install/ para checar a instruções detalhadas para o seu sistema operacional.
Iremos aproveitar as imagens já construídas, disponíveis no Docker Hub (https://hub.docker.com). Vamos utilizar a imagem do PHP 7.2-fpm e a nginx:latest. Felizmente podemos utilizar o próprio docker compose para recuperar essas imagens, sem precisar necessariamente acessar o site.
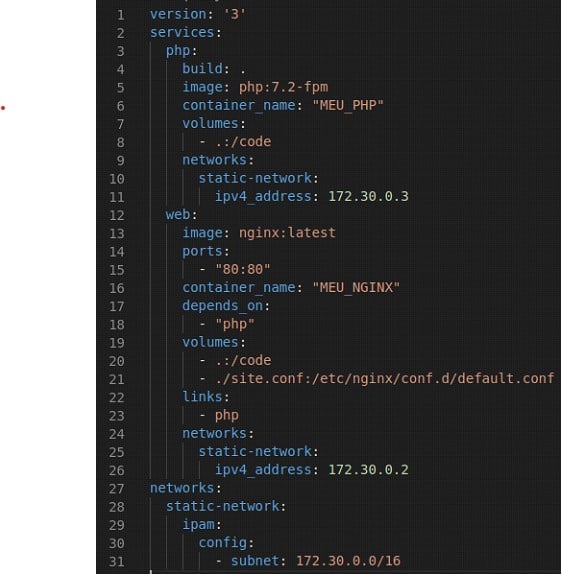
Crie uma nova pasta para o seu projeto, e crie um arquivo chamado docker-compose.yml. O arquivo final vai ser parecido com este:
Vamos analisar cada um dos campos:
version – Indica qual a versão do compose que sendo utilizada. Neste caso a versão 3. services – Define os serviços que serão iniciados pelo compose. php | web – O identificador do serviço. Pode ser qualquer nome alfanumérico. ports – Expõe portas do container. A sintaxe é feita de “{porta_de_origem}:{porta_de_destino}” build – Campo que indica diretório onde está as configurações que serão aplicadas em tempo de build. Como utilizaremos os arquivos na mesma pasta, utilizamos o . (ponto) para indicar o diretório atual. Tal parâmetro é utilizado apenas no serviço do PHP, pois, o servidor nginx não exige configurações adicionais. image – Indica o nome da imagem que será utilizada pelo serviço. Pode ser encontrado no Docker Hub. container_name – Nome do container. É usado apenas como um identificador na hora de executar comandos no container. volumes – Aqui podemos realizar um link de nossas pastas para dentro do container. Na forma de {origem}:{destino}. É importante notar que, os volumes (pastas, subpastas e arquivos) caso sejam alterados no host , vão refletir dentro do container e vice-versa. Caso deseje que sejam independentes, procurar pelo comando COPY no Dockerfile depends_on – Lista os serviços pelos seus indicadores, pelo qual o serviço atual precisa esperar para começar a se iniciar. links – Indica ao serviço, aos quais outros ele deve estabelecer uma conexão de rede. Neste caso o Nginx está linkado com o php pois precisa repassar as solicitações de arquivos php para o FastCGI. Perceba que o nginx solicita ao PHP e pega o retorno, mas, o php nunca faz uma solicitação direta ao nginx, sendo desnecessário estabelecer a conexão nas duas direções. networks – Podemos estabelecer ou não uma rede e utilizá-las em um serviço. É ideal para manter os endereços constantes e não variar cada vez que um container novo é criado.
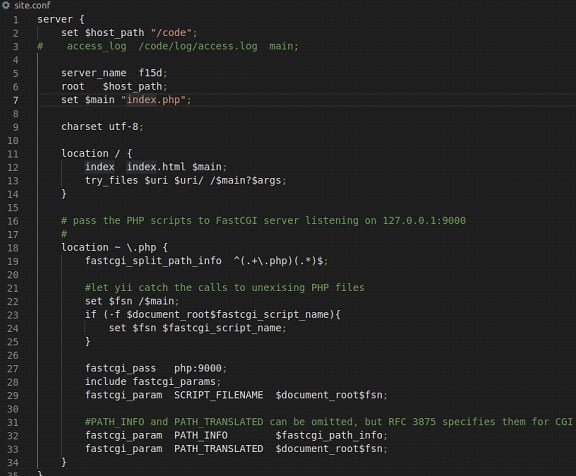
No Nginx utilizamos um arquivo site.conf, para realizar as devidas configurações de integração com o FastCGI. É importante não esquecer da indentação e dos hífens (-) para que não ocorra erro na hora do build.
site.conf
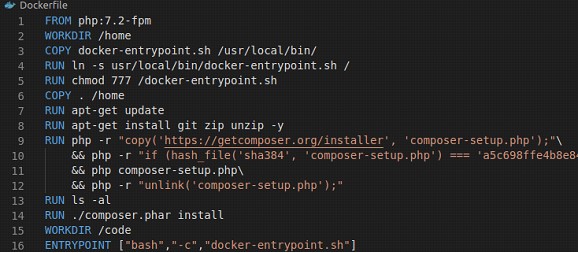
Vamos agora a criação do Dockerfile.
Vamos destacar apenas os pontos essenciais:
FROM php:7.2-fpm – Indica que todos os comandos abaixo dessa linha serão executados no container que possui a imagem php:7.2-fpm.
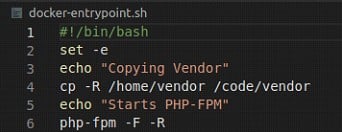
O que fazemos aqui é copiar nosso código fonte para a pasta /home, baixar e instalar o composer (poderíamos também utilizar a imagem pronta), instalar os pacotes do composer e setar a pasta padrão como /code. No final colocamos um script personalizado de execução, que fará a cópia da pasta /home/vendor para a /code/vendor.
Um dos motivos de utilizar um script personalizado, é que como estamos realizando um link da pasta com o host, se realizarmos a instalação de maneira direta, o link é feito depois da execução do Dockerfile, logo, todos os arquivos do vendor serão apagados. É possível superar essa dificuldade usando fases intermediárias de build no Docker, mas, não será nosso caso no momento.
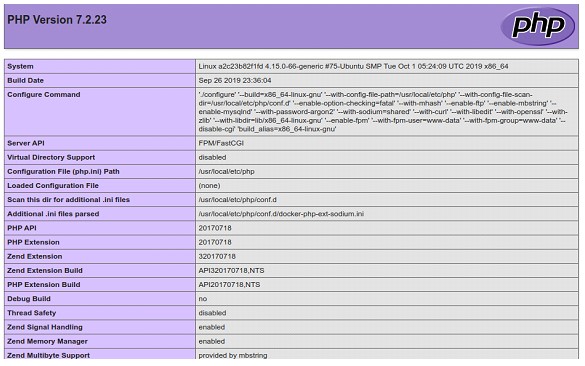
Podemos colocar na raiz do nosso projeto um arquivo index.php:
<?php phpinfo(); ?>
Com toda a configuração realizada, basta executar dentro da pasta:
$ docker-compose up
E devemos ver a seguinte tela:
É possível que seja necessário executar os comandos com o docker em modo de administrador ou caso deseje executar no modo normal, veja este guia: https://github.com/sindresorhus/guides/blob/master/docker-without-sudo.md
Conclusão
Em resumo, a tecnologia Docker é uma abordagem mais granular, controlável e baseada em microsserviços que valoriza a eficiência. Uma vez que todo o processo (Dockerfile, docker-compose, scripts auxiliares) tenham sido completados, basta copiar os arquivos para o servidor, instalar o docker e executar o docker compose. Dessa forma, teremos todo o ambiente devidamente configurado e pronto para uso.
Links
PHP-FPM – https://hub.docker.com/_/php?tab=tags
Nginx – https://hub.docker.com/_/nginx
Dockerfile – https://docs.docker.com/engine/reference/builder/
Docker Compose – https://docs.docker.com/compose/
Página Oficial do Docker – https://www.docker.com/
Docker Compose Versão 3 – Referência – https://docs.docker.com/compose/compose-file/#build
Nos dias atuais, há um aumento crescente na preocupação sobre a segurança relacionada à infraestrutura mantida na nuvem pelas organizações. Desta forma, procuram-se maneiras de manter um nível de confiabilidade e controle que permita a disponibilidade necessária aos serviços oferecidos. Hoje, iremos aprender como obter informações sobre acessos realizados ao servidor. Estaremos usando a distribuição linux ubuntu 18.04 LTS, podendo assim, algumas funcionalidades estarem indisponíveis ou ter seu acesso de maneira diferente.
Glossário de Termos.
Host ─ Qualquer computador, servidor cloud, máquina virtual em que se esteja trabalhando.
Terminal ─ Uma interface de linha de comando instalada nas distribuições unix.
$─ Símbolo para indicar um terminal shell/bash. Não deve ser copiado junto aos comandos.
[identificador] ─ Valor opcional e que deve ser substituído pela sua própria informação
O comando last
Com o comando last, é possível obter ainda mais informações sobre os usuários ─ terminais usados, quando autenticaram, quando saíram, etc. ─ É utilizado o arquivo /var/log/wtmp, o qual é lido para exibir uma lista de todos os usuários que se autenticaram, desde que ele foi criado.
Para executar, basta que abra o terminal do seu host e digite:
$ last [nome_de_usuario]
Caso se queira filtrar os registros por um usuário específico, é possível especifica-lo (sendo opcional) diminuindo assim o número de registros. Caso ainda haja dificuldade na leitura, devido a uma grande quantidade de acessos, é possível ainda paginar a consulta. Basta executar:
$ last [nome_do_usuario] | less
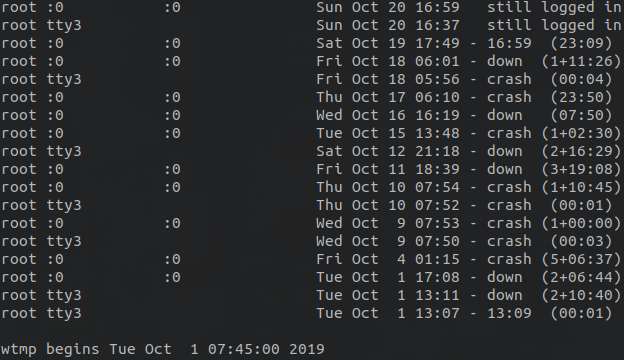
A saída do comando deve ser similar a exibida a seguir:
Iremos nos preocupar apenas com algumas colunas. Na primeira coluna, podemos observar o nome de usuário que realizou o acesso, neste caso foi o usuário root. Na quarta coluna a data de entrada e saída do sistema e por fim na quinta coluna, indicando a situação em que o terminal utilizado por aquele usuário se encontra.
Observando a quinta coluna, algumas situações possíveis considerando sua formatação são: Data –still logged in. Indica que o usuário acessou o host em determinada data/horário e o mesmo ainda se encontra ativo. Data – down (time). Indica que o usuário acessou o host em determinada data, e algum tempo depois, o host foi desligado ou reiniciado com o usuário ainda logado. Data – crash (time). Indica que o usuário acessou o host em determinada data, e algum tempo depois, houve uma falha crítica, fazendo o host ser encerrado. Mostra que não foi desligado de maneira apropriada. Data – Data. Indica o horário de entrada e saída do usuário, indicando que não houve uma mudança de estado no servidor.
Utilizando da ferramenta grep é possível realizar alguns filtros que agilizem a busca por informações mais específicas. Por exemplo, caso queiram procurar quais foram os acessos do usuário root, no dia 19 de outubro, basta executarmos:
$ last root | grep -i “Oct 19”
Como pode-se observar, apenas os acessos feitos nessa data serão exibidos. O mesmo pode ser feito para algum dia da semana, como segunda ou sábado. É importante notar que, a forma em que a data está sendo exibida, vai depender do idioma do sistema operacional que está sendo executado. O padrão utilizado aqui é o americano, mas, você deve se atentar para, caso necessário realizar as devidas modificações na hora de executar os comandos.
O servidor também registra as ações de reinício de sistema, podendo recuperaadas utilizando o comando:
$ last -x reboot
Para casos em que o sistema foi desligado, usa-se:
$ last -x shutdown
Um último comando que é bastante útil é o lastlog. Ele mostra a última vez em que cada usuários auutenticou no sistema. assim como no last podemos fazer uma busca por um usuário em específico utilizando:
$ lastlog -u root
Entretanto, o lastlog possui uma funcionalidade que apenas o last não é capaz de fornecer com a mesma facilidade, que é obter lista de usuários que se autenticaram nos últimos x dias. Basta que executemos:
$ lastlog -t 10
E teremos a lista de usuários que entraram no sistema nos últimos 10 dias. Também é possível pedir a lista de pessoas que acessaram a mais de x dias. Basta trocar o parâmetro -t por -b:
$ lastlog -b 10
É importante preservar todos os registros de acesso, pois os mesmos dão indícios sobre possíveis culpados ou a inocência de alguém diante à algum incidente. Pois, se o mesmo não realizou nenhum acesso durante o período do problema, é improvável que o mesmo tenha alguma relação. Ainda assim, talvez queiramos limpar o histórico de registro ou em outro caso, realizar um backup. Basta que seja apagado ou copiado o arquivo /var/log/wtmp e o procedimento estará feito. Em relação ao lastlog o procedimento é análogo, exceto pelo arquivo que se encontra na pasta /var/log/lastlog
É digno de nota que, o arquivo que tem essas informações armazenadas, é um arquivo binário, logo, ele não é legível para humanos e não pode ser alterado diretamente, o que poderia ocasionar o corrompimento do mesmo.
Conclusão
Com ferramentas presentes na maioria dos servidores em nuvem, pudemos facilmente obter informações valiosas sobre o histórico de acesso de usuários que, em geral podem ser colaboradores de uma organização, ou prestadores de serviços externos.
Em sistemas escaláveis, é importante manter uma infraestrutura adequada, de maneira que a aplicação possa suportar grandes quantidades de acesso. O aumento da capacidade do hardware pode se tornar inevitável, entretanto, é interessante avaliar se não há outras alternativas, como por exemplo, a modificação da arquitetura existente. Neste post, veremos como a utilização de um proxy reverso, nos ajuda a gerenciar os recursos de um servidor, para que possam ser aproveitados de melhor maneira, aumentando assim sua performance e segurança.
Proxy Reverso
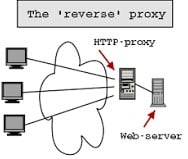
Em primeiro lugar, precisamos entender do que se trata um proxy reverso. Um proxy reverso é um servidor de rede geralmente instalado para ficar na frente de um servidor Web. Todas as conexões originadas externamente são endereçadas para um dos servidores Web através de um roteamento feito pelo servidor proxy, que pode tratar ele mesmo a requisição ou encaminhar a requisição toda ou parcialmente a um servidor Web, que tratará dela.
Um proxy reverso repassa o tráfego de rede recebido para um ou mais servidores, tornando-o a única interface para as requisições externas. Por exemplo, um proxy reverso pode ser usado para balancear a carga de um cluster de servidores Web. O que é exatamente o oposto de um proxy convencional, que age como um despachante para o tráfego de saída de uma rede, representando as requisições dos clientes internos para os servidores externos à rede a qual o servidor proxy atende.
Configurando
É importante conhecer bem a sua atual infraestrutura de servidores, pois a configuração irá variar de ambiente para ambiente. No caso aqui apresentado, será utilizado o Nginx como proxy reverso para um servidor web, apache.
Para começar, será necessário realizar a instalação o Nginx. No sistema operacional ubuntu 18.04, é possível o fazer executando os seguintes comandos:
sudo apt-get update
sudo apt-get install nginx
Caso você seja usuário do docker, dentro do meu repositório, eu disponibilizei um arquivo para configuração inicial dos serviços. Ele se encontra aqui:
Basta alterá-lo de maneira que se adeque ao seu ambiente, quer seja de desenvolvimento ou em produção.
Uma vez que o nginx esteja instalado, você pode checar o status do serviço utilizando o seguinte comando:
service nginx status
O mesmo deve retornar uma mensagem:
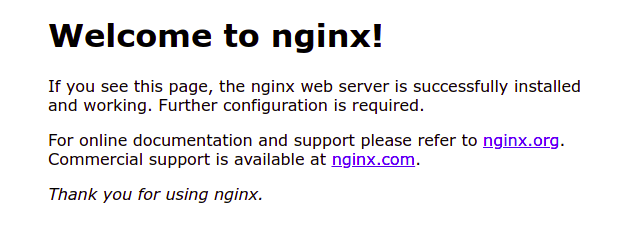
Ao acessar o navegador e digitar o endereço(domínio ou ip) em que o servidor foi instalado, a tela inicial do nginx deverá estar visível:
Como o Nginx vai ser a porta de entrada para os nossos serviços, é necessário que o mesmo fique alocado na porta 80 (por padrão ele é configurado nessa porta durante a instalação) do seu servidor, que é a mesma porta padrão de acesso às páginas web. Consequentemente seu servidor web, caso esteja no mesmo endereço de ip, entrará em conflito e então precisará ter sua porta de acesso alterada. Basta escolher qualquer porta que não seja destinada a nenhum outro serviço. Você pode conferir o conjunto de portas reservadas neste link:
É aconselhável que, mesmo que os servidores estejam em endereços de ip diferentes, seja alterada a porta, pois torna o seu servidor menos visível para acessos externos.
Vamos fazer com que nosso nginx, faça o redirecionamento para o nosso servidor apache. Abra o arquivo /etc/nginx/conf.d/default.conf e altere o location para que ele se pareça mais com este:
Onde temos http://173.20.0.2 alterar para o endereço de ip do seu servidor. e execute o comando:
service nginx reload
Caso não haja nenhum erro após executar o comando, ao acessar o mesmo endereço, verá que não aparece mais a tela inicial do Nginx mas sim a do seu servidor. Além disso, é possível modificar as configurações de forma que o Nginx possa servir diretamente os arquivos estáticos como html, css e javascript tornando a resposta mais rápida. Todas as requisições dinâmicas tais como as realizadas para servidores php, python, nodejs, outras apis, podem ser encaminhadas para os seus respectivos servidores, devidamente processadas e retornadas.
Vantagens
Como existe uma camada a mais entre o cliente e a sua aplicação, ela adquire uma “camuflagem”, não sendo diretamente visível por quem acessa externamente.
É simples de implementar e proporcionar ao usuário segurança de ponta contra ataques a servidores web como DDoS e DoS
O Proxy Reverso Nginx ajuda a criar uma carga equilibrada entre vários servidores back-end e proporciona cache para um servidor back-end mais lento
O Nginx não exige a configuração de um novo processo para cada nova solicitação da web vinda do cliente. Ao invés disso, a configuração padrão é para incluir apenas um processo de trabalho por CPU
Pode agir como um servidor Proxy Reverso para vários protocolos como HTTP, HTTPS, TCP, UDP, SMTP, IMAP e POP3
Ele pode operar mais de 10000 conexões com uma pequena pegada de memória. O Nginx pode operar múltiplos servidores da internet através de um único endereço de IP e entregar cada solicitação para o servidor dentro de uma LAN
O Nginx é um dos melhores servidores da web para melhorar o desempenho de conteúdo estático. Adicionalmente, pode ser útil servir conteúdo em cache e executar criptografia SSL para diminuir a carga do servidor
Pode ser útil na hora de otimizar conteúdos ao comprimi-los para melhorar o tempo de carregamento
O Nginx pode executar experimentos aleatórios ou testes A/B sem posicionar códigos JavaScript nas páginas.
Conclusão
Como toda e qualquer outra técnica ela precisa ser aplicada de maneira correta. Dentro de uma aplicação com 100 requisições por minuto e outra com 10 mil, a visibilidade do ganho de performance, é bem diferente, apesar de continuar existindo. Ao querer expor novos serviços, ganhamos uma simplicidade no processo, pois, basta que os mesmos sejam configurados e posteriormente alterar as configurações no proxy reverso de forma que os tornem visíveis, oferecendo assim um controle centralizado e performático.
Com os avanços tecnológicos e a velocidade com que as informações circulam atualmente, o ambiente, a sociedade e os negócios mudam constantemente, acompanhando as demandas e variações. Para manter-se, então, competitivo nesse ambiente, para garantir a produtividade das empresas é preciso, cada vez mais, produzir de forma eficiente, com o menor custo possível e de forma integrada.
Porém, em um ambiente tão veloz, a integração das informações e das atividades, consequentemente, pode ser um verdadeiro desafio para alguns negócios. Principalmente, para quem está começando o próprio negócio, é fundamental contar com uma parcela desses investimentos em tecnologia da informação, aplicativos e softwares que tenham a capacidade de garantir a integração entre os indicadores de performance afim de agregar valor as estratégias e ao produto / serviço em si.
Nesse cenário, o uso dos APIs se torna essencial para as empresas. Pensado nisso, nesse artigo, buscamos responder à principais dúvidas em torno do assunto.
O que são APIs?
A sigla API vem do termo em inglês Application Programing Interface, que em tradução livre, significa interface de programação de aplicativos. Ou seja, uma aplicação que permite que um determinado software se comunique ou interaja com algum outro, promovendo uma integração das informações e do ambiente de trabalho, consequentemente, o que pode reduzir o índice de retrabalho ou duplicidade de atividades, por exemplo.
Logo, o objetivo principal para o uso e aplicação de APIs em uma empresa é exatamente aumentar a sua produtividade, a segurança das informações e, dessa forma, aumentar os resultados dos negócios.
Porém, para garantir que todos esses desejos sejam alcançados é preciso ter clareza do real objetivo que se pretende traçar uma estratégia clara e robusta, que envolva a maior quantidade de variáveis do negócio assim como também tenha acesso a informações e dados de qualidade.
Integrando com APIs
A integração dos negócios através das APIs funciona de forma similar a um processo de compra online. Você, enquanto cliente, acessa um determinado site e faz um pedido de compra.
A administração do site ou fornecedor, interpreta o seu pedido e articula os meios de entregá-lo a você.
Esse é o papel das APIs: receber o pedido de um ponto de partida, nesse caso de um cliente, processá-lo de forma adequada, e depois levar o produto até o cliente, como resposta do seu pedido.
As APIs, então, tem a função de receber uma informação ou questionamento e transformá-la em uma resposta. Sua aplicação elimina, por exemplo, a atividade de receber uma determinada informação em uma planilha e ter que transportá-la para outro programa afim de obter a resposta desejada.
Como aumentar a produtividade de empresas com o uso de APIs
Com a descrição do funcionamento dada anteriormente, fica claro como o uso e aplicação de APIs aos negócios é capaz de aumentar a produtividade e alavancar os resultados de uma empresa.
Quando analisamos, porém, uma única atividade (uma única compra online) isso pode não ser muito claro. Contudo, imagine a situação que você more em um condomínio, onde residem outras 150 pessoas. Todos vocês desejam comprar um livro em um mesmo site de compras online. Imagine, agora, que a administração desse site, precise atender todos os esses pedidos de forma simultânea e entregá-los na mesma data. Se o administrador decidir por processar e entregar um pedido de cada vez na ordem com que chegam à sua “mesa” certamente o dono do ultimo pedido terá que esperar bastante.
Porém, se esse administrador utilizado uma API, ele conseguirá ler e programar os 150 pedidos de forma simultânea e, principalmente, instantânea, garantindo a entrega no menor espaço de tempo possível e aumentando, consideravelmente, sua produtividade nas compras online.
Se você não estava cogitando utilizar uma API nos seus negócios para aumentar a produtividade da sua empresa, é melhor pensar com mais carinho a respeito.
Podemos imaginar os servidores como um restaurante, podemos escolher um que trabalhe com autoatendimento e que sai bem mais em conta, ou optamos por aqueles com atendimento em mesa, onde recebemos toda ajuda que precisamos para entender os pratos da casa.
Por acaso você já teve a experiência um tanto quanto frustrante, de entrar em um restaurante self service, montar o seu prato com as opções que estavam disponíveis e só depois descobrir que eles estão servindo algo que você realmente queria comer e acaba não tendo nada haver com o prato que você montou? Pois é disso que se trata, nos restaurantes self service os preços saem bem mais em conta, mas em um restaurante que possui atendimento dos garçons você não passaria por este tipo de situação.
Mas afinal de contas, o que tudo isso têm a ver com com os servidores dedicados? Vamos entender melhor a seguir.
O que é um servidor dedicado em nuvem?
Um servidor é basicamente um computador com processadores, bancos de memórias, portas para comunicação e sistema para armazenagem de dados. Eles fornecem serviços à várias outras máquinas através da execução de programas e protocolos. A principal diferença de um servidor para um computador normal, é que os servidores possuem componentes fabricados especificamente para trabalhar de forma ininterrupta ou seja eles ficam 24 horas online.
Os servidores na nuvem podem ser compartilhados entre muitos clientes de modo que seus vários recursos sejam distribuídos, porem a tecnologia em nuvem mesmo sendo compartilhada entre vários clientes ela não interfere em nada na qualidade do servidor, ou seja apesar de rodar em um ambiente virtual ela conta com a mesma tecnologia de um servidor o 100% dedicado.
Mesmo rodando em ambiente compartilhado ele é 100% dedicado ao cliente e neste caso, os recursos do servidor serão utilizados exclusivamente por ele não existindo restrição de recursos , isso significa que a RAM, CPU, HD e largura de banda serão usados de acordo com a vontade do cliente.
você têm pleno acesso ao sistema e pode personalizar o servidor como desejar, inclusive o software.
Qual a vantagem de contratar a nuvem?
Para explicar melhor a finalidade dos servidores dedicados, usaremos um exemplo muito simples, vamos dizer que você fará uma viagem com um amigo e vocês decidem ir de ônibus, não existe a mínima necessidade de alugar um ônibus apenas para vocês dois, seria um desperdício de dinheiro, uma vez que existe uma opção muito mais barata. Mas e se, ao invés do seu amigo, você estiver fazendo uma viagem em família. Com tantas pessoas é muito mais benéfico alugar um ônibus particular, não é verdade?
O mesmo princípio se aplica aos servidores, se você possui uma empresa ou site pequeno, que ainda está começando e não têm muitos acessos, uma hospedagem de site é uma opção muito mais barata e vai dar conta do recado. Mas se você possui uma grande empresa ou e-commerce de sucesso, um servidor em nuvem vai evitar problemas de performance e erros, além de aumentar a segurança.
Servidor dedicado com gerenciamento básico
Então, com esse tipo de gerenciamento, você fica responsável pelo gerenciamento do servidor e precisa cuidar das atualizações, correções, configurações e segurança. Possui apenas suporte apenas em emergências, como defeitos no hardware e falhas no sistema operacional. Esta opção de gerenciamento é mais barata, entretanto, ela exige um alto nível de conhecimento técnico e preparação da equipe.
Servidor dedicado com gerenciamento avançado: Motorista particular
Com esse gerenciamento, quem ficará responsável por toda a manutenção e correções do servidor é a empresa contratada. Apesar de ser um serviço adicional, o gerenciamento avançado vai te economizar tempo e trabalho, e pode até mesmo economizar recursos caso você não disponha de uma equipe especializada a sua disposição ou não tenha muito experiência com servidores.
Qual delas é a melhor opção?
Isso é algo que realmente não podemos dizer, uma vez que as duas opções possuem vantagens e podem auxiliar diversos modelos de negócios. Para decidir qual escolher, você deve avaliar qual é a necessidade do seu negócio.
Você poderá determinar se um servidor dedicado é necessário para o seu negócio, ao estudar o crescimento da audiência e utilização dos recursos.